
Enhancing Deep Learning Performance with Triton and PyTorch - vector add example with IRs

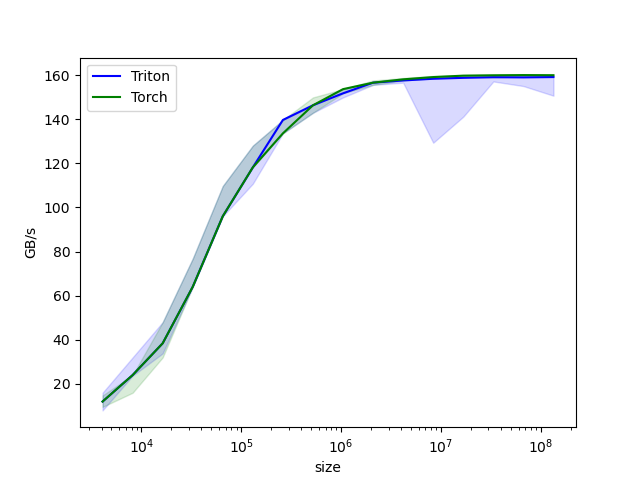
Generated by my old NVidia GTX 1060 GPU
Introduction
In the rapidly evolving field of deep learning, the efficiency of operations is paramount. Triton, as a language and compiler, emerges as a powerful tool, enabling custom deep learning operations with remarkable efficiency. Paired with PyTorch, it opens up new possibilities for optimization. This blog post delves into a practical example of vector addition using Triton, highlighting its Intermediate Representations (IRs) and comparing its performance with PyTorch.
Keep reading with a 7-day free trial
Subscribe to Hao’s Tech Channel to keep reading this post and get 7 days of free access to the full post archives.